
🔗 이 글은 Raluca Budiu가 Nielsen Norman Group에 올린 아티클을 번역, 요약한 글입니다.
⚡️요약
사용자 리서치에서 크게 두 가지 방법이 있고, 두 방법의 특징을 알고 더 좋은 방법을 선택해야 한다
- 반복 측정 설계는 참가자 간 차이를 상쇄할 수 있지만, 학습 효과를 방지하기 위해 랜덤화를 사용해야 하고
- 독립 집단 설계에서는 조건 간 학습 효과를 상쇄할 수 있지만, 참가자 간 차이를 상쇄할 수는 없음
용어 정리
Between-Subjects Study Design: 독립 집단 설계
Within-Subject Study Design: 반복 측정 설계
한 조사에서 여러 사용자 인터페이스를 비교하려 할 때, 다음과 같은 조건들로 실험 참가자에게 태스크를 부여할 수 있다.
- 독립 집단 설계: 각 실험 조건에 각기 다른 사람이 참여함. 한 사람은 한 인터페이스에만 노출될 수 있도록 함
- 반복 측정 설계: 동일한 사람이 모든 실험 조건에 노출되도록 함
정량적 조사에서 실험 디자인
주로 정량적 사용성 조사는 비교하는데 핵심 목표를 둔다. 예를 들어 경쟁사의 웹사이트, 다른 두가지 버전의 디자인, 사용자 그룹의 두 종류(experts vs. novices) 간 비교가 있다. 이 때 정량적 분석에서는 두 가지 변수가 있다.
독립 변수(Independent variables): 리서처에 의해 직접적으로 조정되는 것
종속 변수(Dependent variables): 측정되는 것 (그리고 독립 변수의 조정에 따라 결과가 달라질 것으로 예상되는 것)
만약 조사가 통계적으로 유의미한 결과를 만든다고 했을 때,
독립 변수의 조정이종속 변수의 변화를야기했다고 할 수 있다.
자동차 렌트 사이트의 예시로 돌아가보자.
두 렌탈 사이트중 자동차를 렌트하는데 더 나은쪽이 어디인지 알고 싶다면, 사이트를 독립 변수로, 태스크를 수행하는데 걸리는 시간과 정확도를 종속 변수로 둘 수 있다. 이 때 조사의 결과는 종속 변수인 시간과 정확도가 사이트를 다르게 할 때 달라지거나 동일하게 유지되는 것으로 나올 수 있을 것이다(만약 동일하게 유지된다면, 두 사이트 중 더 나은 곳은 없다는 의미)
이 때 조사를 위한 실험 방법을 선택하는 것은 데이터를 통계적으로 분석하는 방법에 영향을 준다.
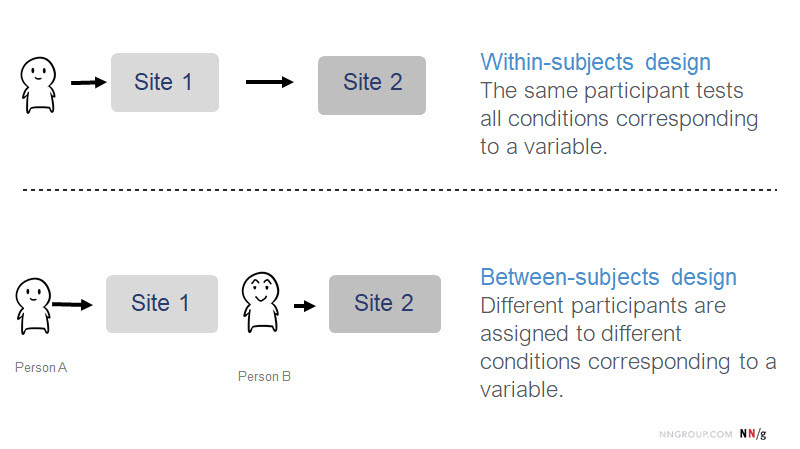
실험 방법은 독립 집단 설계이면서 반복 측정 설계일 수 있다.
30살 미만 사용자와 그렇지 않은 참가자 간 비교를 하고 싶을 때, 독립 변수는 두가지가 된다
- 나이 - 2가지 타입: 30살 미만, 30살 이상
- 사이트 - 2가지 타입: A, B
예를 들어, 각 연령 그룹에 동일한 숫자의 참가자를 모집하고 각 참가자를 A와 B 사이트 모두에서 자동차 렌탈을 수행한다고 하자.
그렇다면 이 조사는 독립 변수 사이트에 대해서는 반복 측정 설계이고(각 참가자는 두가지 사이트 모두를 보게 되니까),
독립 변수 나이에 대해서는 독립 집단 설계가 된다(각 참가자는 30살 미만이거나 30살 이상이며, 둘 다일 수 없음).
30살 미만의 참가자를 30살 이상이될 때 까지 기다렸다가 다시 조사를 한다면 반복 측정 설계가 될 수 있겠지만, 현실적으로 말이 되지 않음
일부 독립 변수의 종류는 디자인 방법에 영향을 준다.
예를 들면 위와 같이 나이, 전문성, 사용자 타입 (business traveler, leisure traveler), 성별 (한 사람이 한 성별만 가지고 있다고 가정하면)과 같은 변수가 그렇다.
사용성 뿐 만 아니라 약물 실험과 같은 경우도 독립 집단 설계일 수 밖에 없다. 각 참가자는 두 가지 모든 약에 노출되지 못하고, 한 종류의 약물에만 노출되어야 한다.
또 변수의 조작 자체가 참가자에게 영향을 줄 수도 있다. 읽기에 더 도움되는 교수법을 확인하고 싶을 때, 한 사용자는 이전의 교수법에서 읽기 능력이 향상되었을 수 있으므로 두 가지 방법을 모두 사용할 수 없다.
독립 집단 설계 vs 반복 측정 설계 어느 것이 더 나을까
답은 언제나 그렇듯 “때에 따라서 다르다” 이다.
- 독립 집단 설계는 학습 효과와 조건 간 방해 효과를 최소화 할 수 있다
한 사이트에서 자동차를 빌려 본 참가자는 자동차 렌탈 과정에 대해 더 잘 알게될 것이다. 이러한 지식은 두 번째 사이트에서 더 효율적으로 태스크를 수행할 수 있도록 할 것이다. - 독립 집단 설계는 반복 측정 설계보다 더 짧은 세션 시간이 소요된다
두 번 측정하는 것 보다 짧은 시간이 소요되는 것이 덜 지치고 덜 지루할 것이다. 또 원격 조사나 연구자가 함께하지 않는 조사에서 더 유용할 수 있다. - 독립 집단 설계는 더 많은 독립 변수가 있을 때 더 설계하기 쉽다
설계 순서에 따른 노이즈를 최소화 하기 위해 랜덤화를 사용해야 한다. 모든 사용자에게 사이트 A 다음 사이트 B를 수행하도록 하지 않아야 할 것이다. 두 개 사이트에 대한 실험은 설계하기 쉽지만, 독립 변수가 많거나 한 변수의 레벨이 다양해지는 경우 현존하는 정량적 조사 플랫폼에서 랜덤화를 도입하기 어려울 것이다. - 반복 측정 설계는 더 적은 참가자로 더 저렴하게 수행할 수 있다
정량적 조사 방법에서는 보통 각 조건 별로 30개 이상의 데이터 포인트를 가져야 통계적 유의성을 확보할 수 있다. 독립 집단 설계에서는 두 사이트 모두에서 30명의 참가자가 필요하지만, 반복 측정 설계에서는 두 사이트를 합쳐 30명의 참가자만 있으면 된다. 두 배나 저렴하다 - 반복 측정 설계는 랜덤 노이즈를 최소화 한다
💎이것은 반복 측정 설계의 가장 큰 장점이다.
모든 참가자들은 각자 자신의 백그라운드, 컨텍스트, 상황을 가지고 있을 것이다. 동일한 참가자가 변수의 모든 레벨과 상호작용 하면, 전체에 대해 모두 동일하게 영향을 주고받게될 것이다.
독립 집단 설계일 경우 만약 행복한 사람과 피곤한 사람이 실험에 참여했을 경우 결과가 원하는대로 나오지 않을 수 있다. 독립 집단 설계에서 각 집단 참가자들을 다른 집단 참가자들과 성향, 백그라운드, 컨텍스트, 상황을 일치시키는게 좋지만, 이 모든것을 예측해서 참가자를 구하기란 불가능하다.
랜덤화는 두 방법 모두에서 필요
반복 측정 설계에서 랜덤화가 필요한 이유는 실험의 순서에서 오는 학습 효과와 조건 간 전이 효과를 반감시키기 위한 것이다.
독립 집단 설계에서 랜덤화는, 참가자가 각 조건에 랜덤하게 배정되어야 한다는 의미이다. 리서처가 좋아하는 사람들을 사이트 A에 배정하고 그 결과가 B보다 좋았다고 하면 안된다는 것이다.
결론
사용자 조사는 독립 집단 설계일 수 도 있고, 반복 측정 설계일 수도 있다. 둘 다 일 수도 있고. 각각의 조사 방법은 장단점이 있으니 이를 잘 고려해 방법을 선택해야 할 것이다.
요약하자면, 다음과 같다
- 반복 측정 설계
- 더 적은 참가자
- 더 싼 실험 가격
- 조건 간 진짜 차이를 알 수 있음
- 독립 집단 설계
- 조건 간 학습 효과의 최소화
- 더 짧은 세션 시간
- 더 쉬운 설계와 더 쉬운 분석
덧, 이 아티클의 내용을 읽으니 📕 원인과 결과의 경제학 책이 연상되었다 👇
이 아티클과 원인과 결과의 경제학은 독립 변수를 조정하여 실험한 결과에서 종속 변수가 변화 했을 때, 독립 변수가 정말로 종속 변수의 변화를 야기 했는지 통계적 유의미성을 확보하기 위한 방법에 대해 말하고 있는 점이 유사했다. 이 아티클에서는 조사 방법론 측면에서 두 방법과 각 방법의 유의점을 소개했고, 원인과 결과의 경제학에서는 통계적으로 유의미성을 증명할 수 있는 방법에 대한 소개가 담겨있다.
이상적으로는 반복 측정 설계 + 랜덤화를 사용하는 것이겠지만, 독립 변수의 개수가 많아진다거나, 조사 설계와 분석 방법에서 걸림돌이 있을 수 있겠다. 통계학에 대한 궁금증이 늘어간다.